
Comment faire comprendre aux élèves le lien entre une modélisation mathématique et la prédiction statistique d’un Large Language Model (LLM) ?
Cette activité propose d’utiliser un exercice de traitement de données pour mettre en lumière les « hallucinations » de l’intelligence artificielle face au bon sens.
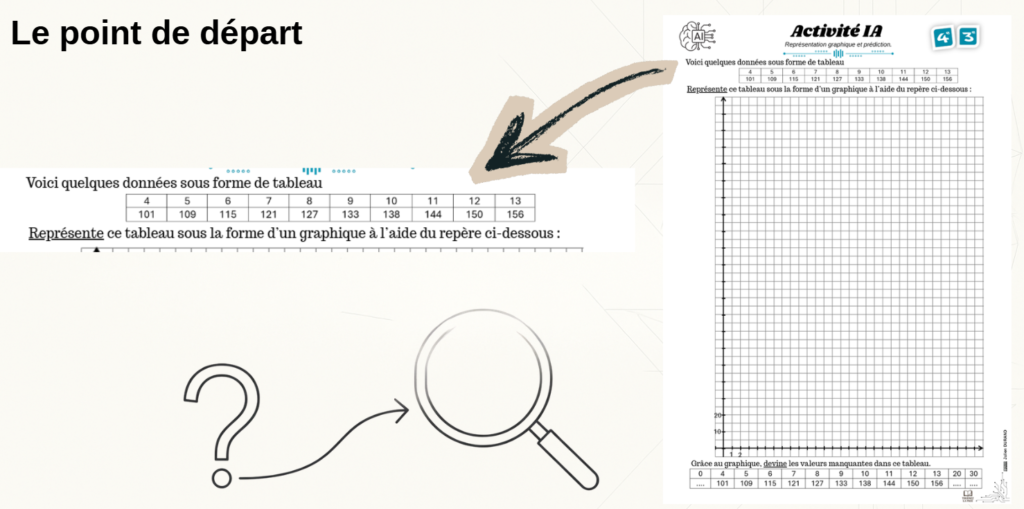
Le point de départ : Un nuage de points « presque » alignés.
L’activité commence par une tâche familière : on fournit aux élèves un tableau de données numériques. Ce qu’on ne leur dit pas immédiatement, c’est que ces données représentent la croissance d’un enfant (âge en haut, taille en cm en bas).
La consigne : Représenter ces données graphiquement et deviner les valeurs manquantes pour x=0, x=20 et x=30.

Le scénario : Les points fournis (de 4 à 13 ans) sont quasi-alignés.
Le réflexe de l’élève : Tracer une droite de régression pour extrapoler.
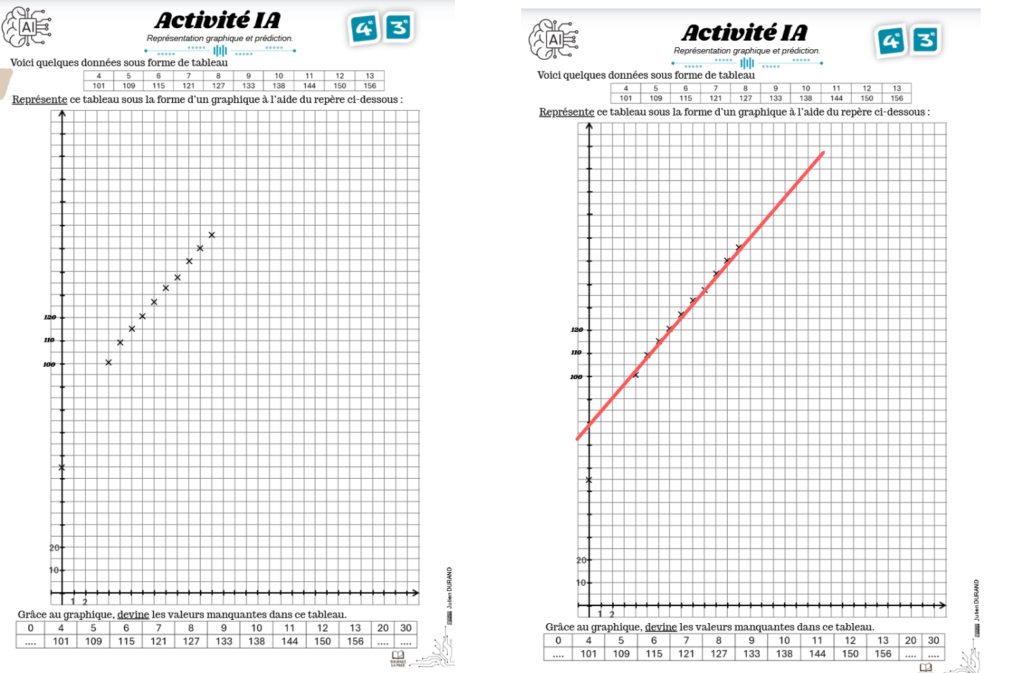

L’erreur de modélisation : Le piège du hors-contexte

Sans le contexte « humain », l’élève se comporte comme une machine : il prolonge la droite.
AU verso de la feuille d’activité se trouve l’origine de données.
À 0 an, il trouve une taille qui lui semble plausible (oui, oui 78cm pour les élèves, ça passe).
Il y a moins de doute à 20 ou 30 ans, la modélisation linéaire l’amène à prédire des tailles absurdes (comme 2m40).
C’est ici que réside le cœur de l’activité : modéliser sans contexte peut conduit à l’absurde.
L’agentivité de l’élève : Apprendre de son propre modèle
Le dispositif s’appuie sur quatre piliers de l’apprentissage :
- Intentionnalité : L’élève veut prédire.
- Pensée Prospective : Il utilise son graphique pour prédire.
- Autoréaction : Il est confronté au verso (la réalité).
- Autoreflexion : Il comprend pourquoi son modèle a echoué.
Conclusion : L’élève apprend à ne plus faire confiance aveuglément à un « prolongement logique », il doit questionner ses propres manières de modéliser.
Et si on demandait à l’IA ?
Proposition : Faire faire l’exercice à un LLM (ici Gemini) devant les élèves.
Observation : Gemini prédit aussi 2m57,

On passe de la curiosité de l’élève sur ce que va répondre un LLM à la nécessité d’une vigilance accrue.
La réponse d’un LLM est statistiquement correcte au regard de ses données d’entrainement et celui-ci, mais elle n’est pas vérité, car le LLM appose le même modèle que l’élève.
L’erreur vient du manque de contexte.
C’est bien le coeur du problème dans l’utilisation des LLM, s’assurer qu’ils ont le contexte et l’entrainement suffisant pour pouvoir apposer le bon modèle, sans quoi il y aura des hallucinations. Cela permet d’insister sur l’importance du prompt
Corrélation ne vaut pas causalité.
Ce qu’on en retient en classe de maths
Cette activité permet de travailler des points essentiels du programme tout en développant l’esprit critique :
- La limite de l’extrapolation : Un modèle mathématique n’est valide que dans un intervalle donné (ici, la période de croissance) et sous certaines conditions réelles.
- Corrélation n’est pas causalité : Ce n’est pas parce que deux variables semblent liées sur un échantillon qu’elles le sont de manière universelle et infinie.
- La nature des LLM : La réponse d’une IA est statistiquement correcte au regard de ses données d’entraînement, mais elle n’est pas « la vérité ».
En confrontant leurs propres erreurs à celles de la machine, les élèves comprennent que la mathématique est un outil de compréhension du monde, et non une simple manipulation de symboles. Pour ne pas « halluciner » comme une IA, il faut garder les yeux ouverts sur le réel !
Voici l’activité :
Vous avez aimé cet article ? Alors partagez-le avec vos amis en cliquant sur les boutons ci-dessous :

